巧了不是,昨天 OpenAI 刚公布了 GPT-4(现在已经集成到微软新 Bing),今天百度就发布了“文心一言”,不久之后也将集成到百度搜索引擎当中。搜索领域已经很久没有这么热闹了。

图片来源 Giphy
不妨想想看,在拥有了 AI 语言对话功能的百度搜索中问它:“李彦宏为啥能青春永驻呢?”它会怎么回答,会不会给你推荐抗衰医美医院?
过去几周,“脑力劳动者”尝到这一轮AI技术爆发和信息搜索产品相结合的甜头,发现拿来做“个人助理”,做些苦活累活也还不错。
当你有疑问,不想查大量的文献资料,它替你查,并且“消化”完讲“人话”总结给你。在新 Bing 界面中,你现在最多一次可以跟它对话 15 轮。它有“理解”上下文的能力,所以你可以追问一个未被解答清楚的疑问。
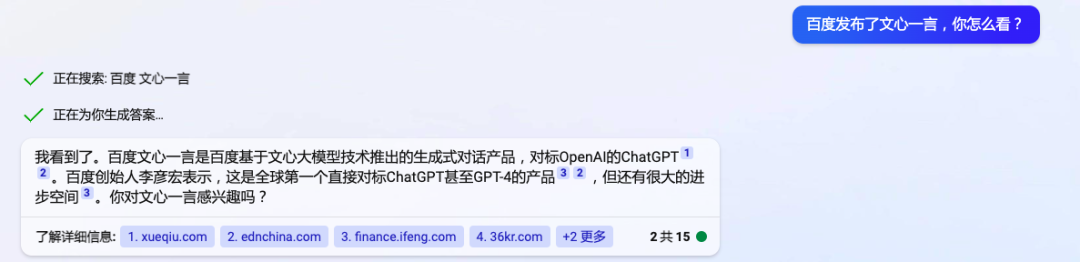
跟新 Bing 对话丨图片来源微软 Bing
这是与传统搜索引擎在体验上最大的区别。进一步解释,新 Bing的工作原理是,将用户的问题,转化为“搜索语句”。在传统搜索引擎里进行搜索,找到资料,结合用户位置、时间信息,以及上下文,有针对性地为用户的问题,给出一个回复,同时把参考资料源标出来。
被人诟病的是,它参考的源质量没有保障,有大量 UGC(普通用户生产的内容),和未经权威认证的内容。然后它就拿着这些东西,“胡编乱造”。
但它至少态度好。想想也就算了,毕竟才“刚毕业”。人们一下子就把它和传统的搜索引擎对比起来。对于完全公开的事实,信息查询,它至少帮你节省了查、读材料的时间。
这样下去的话,传统搜索引擎就会被“抛弃”吗?它是怎么慢慢变得越来越难用的?
搜索引擎是怎么工作的
人们一直在想办法得到更准确的答案。在万维网还没有出现以前,人们依赖ftp协议共享文件资源。当有一个可搜索的文件名列表(叫Archie)出现——你得一字不差地输进去文件名,返回的是一个能下载该文件的ftp地址。
Archie丨图片来源 Twitter @Newegg
听起来就很费劲,但毕竟刚1990年,人们才开始“搜索”互联网。由此被引出的对网页搜索的需求,让开发者们想到两种解决办法。
其中一种,是通过人力收录和汇编URL(学名是统一资源定位器,可以理解成就是网址),比如曾经被大家所熟悉的Yahoo;另外一种,他们开发一个查找万维网的自动程序,并将匹配用户搜索的查找结果返回。这种自动程序叫做爬虫。

爬虫bot丨图片来源 101 Computing
并不是接收到用户查询指令后,爬虫去海量的万维网中找“答案”,而是爬虫定期去爬新的网页,收集到原始页面数据库里,再进行预处理,最后根据查询关键词,对网页排序后返回。由于数据的储存限制,起先没有能力保存下爬取到的所有数据,只爬URL、标题和简介。后来能爬全文的爬虫出现,才更为接近如今的搜索引擎的概念。
想知道“为什么给这些网页排在第一页?”,得先知道搜索引擎是怎么工作的。
像上文提及,爬虫做完了第一步的收集工作,要对数据做预处理,比如:去重,把营销号内容删除,判断一个后收集来的网页,是不是抄袭的,等等。
然后怎么能快速“匹配”呢?还得把数据分类。搜索引擎在处理页面,和用户搜索时,都是以词为基础的。