今晨,一篇来自 Google 内部泄漏的文件在 SemiAnalysis 博客传播,声称开源 AI 会击败 Google 与 OpenAI,获得最终的胜利。 「我们没有护城河,OpenAI 也没有」的观点,引起了热烈讨论。
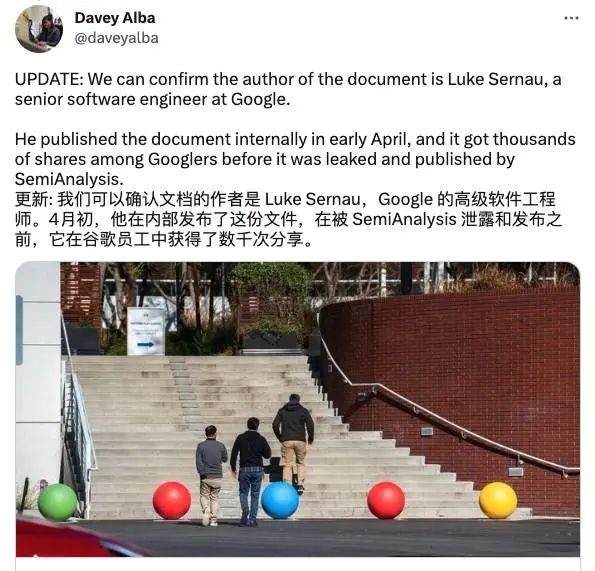
据彭博社报道,此文作者为 Google 高级软件工程师 Luke Sernau,4 月初在 Google 内部发布后就被分享了数千次。
自称 AI-first 的 Google,近几个月以来一直在经历挫败。
2 月,Google Bard 公开演示失误,市值蒸发千亿。3 月,将 AI 整合进办公场景的 Workspace 发布,却被整合了 GPT-4 的 Copilot 抢尽风头。
在赶潮的过程中,Google 一直显得谨小慎微,未能抢占先机。
在此背后,是 Google CEO 皮查伊倾向渐进式,而不是大刀阔斧的改进产品。部分高管也不听从他的调度,或许是因为,大权压根不在皮查伊手里。
如今,Google 联合创始人拉里·佩奇虽然已经不太插手 Google 内部事务,但他仍然是 Alphabet 的董事会成员,并通过特殊股票控制着公司,近几个月还参加了多场内部 AI 战略会议。
Google 面临的问题,每一个都困难重重:
1.CEO 行事低调, 联合创始人拉里·佩奇通过股权控制着公司;
2.「开发产品但不发布」的谨慎,让 Google 多次失去先机;
3.更加视觉化、更具交互性的互联网,对 Google 搜索造成威胁;
4.多款 AI 产品市场表现不佳。
内忧外患之中,Google 被笼罩在类似学术或政府机构的企业文化之下,充斥着官僚主义,高层又总是规避风险。
我们整合翻译了全文,对 Google 来说,开源或许不是压死骆驼的最后一棵稻草,而是它的救命稻草。
核心信息提炼
Google 和 OpenAI 都不会获得竞争的胜利,胜利者会是开源 AI
开源 AI 用极低成本的高速迭代,已经赶上了 ChatGPT 的实力
数据质量远比数据数量重要
与开源 AI 竞争的结果,必然是失败
比起开源社区需要 Google,Google 更需要开源社区
Google 没有护城河,OpenAI 也没有
我们一直在关注 OpenAI 的动向,谁会达到下一个里程碑?下一步会是什么?
但不得不承认,我们和 OpenAI 都没有赢得这场竞争,在我们竞争的同时,第三方力量已经取得了优势。
我说的是开源社区。简单地说,他们正在超越我们。我们认为的「重大问题」如今已经得到解决并投入使用。举几个例子:
手机上的 LLM:人们可以在 Pixel 6 上以每秒 5 token 的速度运行基础模型;
可扩展的个人 AI:你可以一个晚上就在笔记本电脑上微调一个个性化 AI;
负责任的发布:这个问题不是「解决了」,而是「消除了」。互联网充满了没有限制的艺术模型,语言模型也要来了;
多模态:当前的多模态 ScienceQA SOTA 在一小时就能完成训练。
虽然我们的模型在质量方面仍然有优势,但差距正在以惊人地速度缩小。开源模型更快、更可定制、更私密,而且性能更强。他们用 100 美元和 130 亿参数做到了我们使用 1000 万美元和 5400 亿参数下也很难完成的事情。而且他们用的时间只有几周,而不是几个月。这对我们意味着:
我们没有秘密武器。我们最好的方法是向 Google 外的其他人学习并与他们合作,应该优先考虑启用第三方集成。
当有免费、无限制的替代品时,人们不会为受限制的模型付费,我们应该考虑我们真正的价值在哪里。
庞大的模型正在拖慢我们的步伐。从长远来看,最好的模型是可以快速迭代的模型。既然我们知道在参数少于200亿的情况下有什么可能,我们应该更关注小型变体。