
“科大讯飞套壳ChatGPT!”“百度文心一言套皮Stable Diffusion!”“商汤大模型实则抄袭!”……
外界对国产大模型产生质疑已经不是一次两次了。
业内人士对这个现象的解释是,高质量的中文数据集实在紧缺,训模型时只能让采买的外文标注数据集“当外援”。训练所用的数据集撞车,就会生成相似结果,进而引发乌龙事件。
其余办法中,用现有大模型辅助生成训练数据容易数据清洗不到位,重复利用token会导致过拟合,仅训练稀疏大模型也不是长久之计。
业内渐渐形成共识:
通往AGI的道路,对数据数量和数据质量都将持续提出极高的要求。
时势所需,近2个月来,国内不少团队先后开源了中文数据集,除通用数据集外,针对编程、医疗等垂域也有专门的开源中文数据集发布。
高质量数据集虽有但少
大模型的新突破十分依赖高质量、丰富的数据集。
根据OpenAI 《Scaling Laws for Neural Language Models》提出大模型所遵循的伸缩法则(scaling law)可以看到,独立增加训练数据量,是可以让预训练模型效果变更好的。
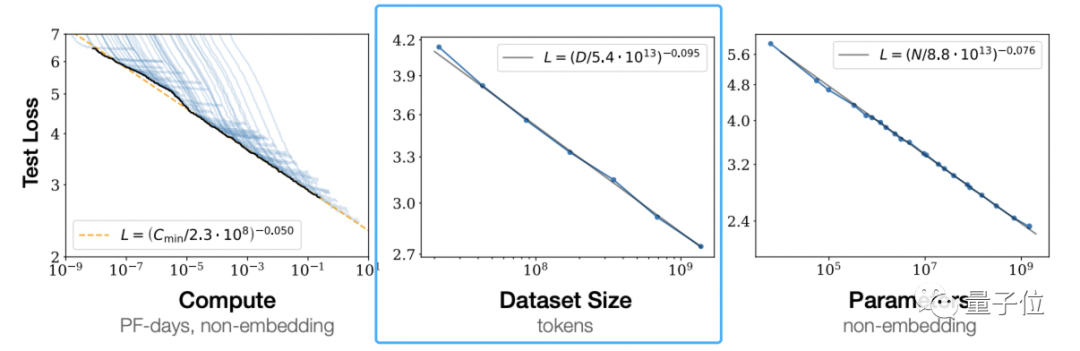
这不是OpenAI的一家之言。
DeepMind也在Chinchilla模型论文中指出,之前的大模型多是训练不足的,还提出最优训练公式,已成为业界公认的标准。
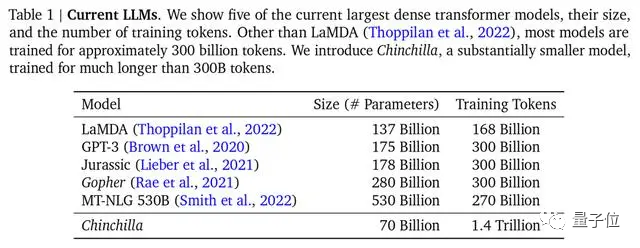 △主流大模型,Chinchilla参数最少,但训练最充分
△主流大模型,Chinchilla参数最少,但训练最充分
不过,用来训练的主流数据集以英文为主,如Common Crawl、BooksCorpus、WiKipedia、ROOT等,最流行的Common Crawl中文数据只占据4.8%。
中文数据集是什么情况?
公开数据集不是没有——这一点量子位从澜舟科技创始人兼CEO、当今NLP领域成就最高华人之一周明口中得到证实——如命名实体数据集MSRA-NER、Weibo-NER等,以及GitHub上可找到的CMRC2018、CMRC2019、ExpMRC2022等存在,但整体数量和英文数据集相比可谓九牛一毛。
并且,其中部分已经老旧,可能都不知道最新的NLP研究概念(新概念相关研究只以英文形式出现在arXiv上)。
中文高质量数据集虽有但少,使用起来比较麻烦,这就是所有做大模型的团队不得不面对的惨烈现状。此前的清华大学电子系系友论坛上,清华计算机系教授唐杰分享过,千亿模型ChatGLM-130B训练前数据准备时,就曾面临过清洗中文数据后,可用量不到2TB的情况。
解决中文世界缺乏高质量数据集迫在眉睫。
行之有效的解决方法之一,是直接用英文数据集训大模型。
在人类玩家打分的大模型匿名竞技场Chatbot Arena榜单中,GPT-3.5在非英文排行榜位居第二(第一是GPT-4)。要知道,96%的GPT-3.5训练数据都是英文,再刨去其他语种,用来训练的中文数据量少到可以用“千分之n”来计算。



