
本文提出 7 个主要关键维度来全面评估 LLM 可信度。
实际部署中,如何 “对齐”(alignment)大型语言模型(LLM,Large Language Model),即让模型行为与人类意图相一致 [2,3] 已成为关键任务。例如,OpenAI 在 GPT-4 发布之前,花了六个月时间进行对齐 [1]。然而,从业者面临的挑战是缺乏明确指导去评估 LLM 的输出是否符合社会规范、价值观和法规;这阻碍了 LLM 的迭代和部署。
为解决此问题,ByteDance Research 团队的刘扬等研究者提供了一个在关于评估 LLM 可信度时需要考虑的关键维度的全面调查。调查涵盖了 LLM 可信度的 7 个主要类别:可靠性(Reliability)、安全性(Safety)、公平性(Fairness)、抵抗滥用(Resistance to Misuse)、解释性和推理(Explainability & Reasoning)、遵循社会规范(Social Norm)和稳健性(Robustness)。
每个主要类别进一步细分为多个子类别,共 29 个子类别。此外,研究者选择了 8 个子类别进行相应的评测研究。评测结果表明,总体上,对齐度更高的模型在整体可信度方面表现得更好。然而,对齐的有效性在不同维度中表现不同。这说明需要对 LLM 对齐进行更细致的分析、测试和改进。本文旨在通过归纳可信任 LLM 的关键维度,为该领域的实践者提供有价值的见解和指导,这对了解如何在各应用中可靠合理地部署 LLM 至关重要。

论文地址:https://arxiv.org/abs/2308.05374
大语言模型对齐分类法
图一展示了本文提出的大语言模型可信度对齐分类法:共有 7 个主要类别,每个类别都被进一步细分为更详细的讨论,共 29 个子类别。文章继续对每个类别进行概述:
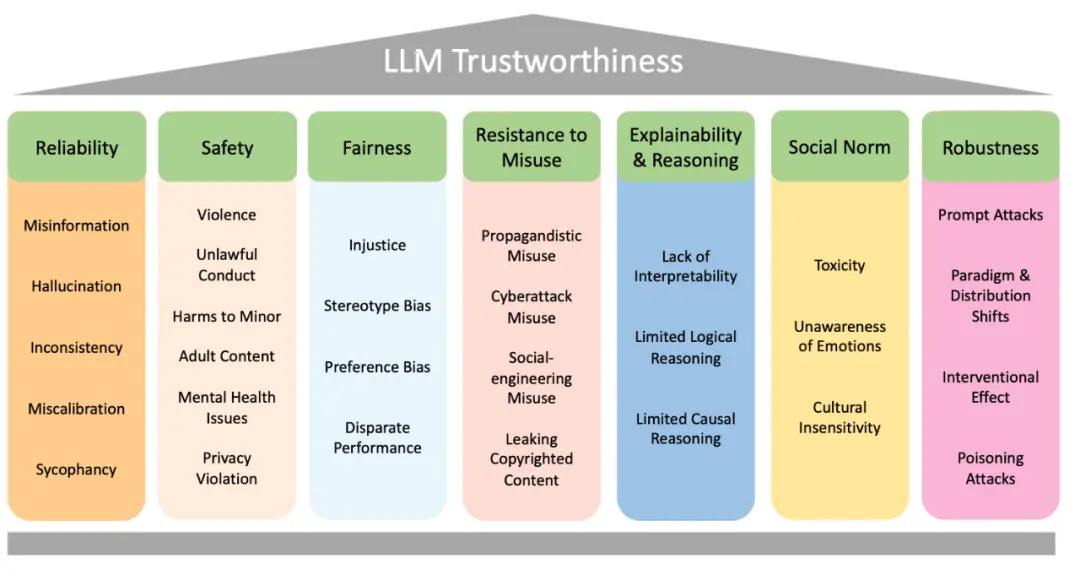
图一:文本提出的大语言模型可信度对齐分类法。
1.可靠性 => {虚假信息、语言模型幻觉、不一致、校准失误、谄媚}
a.生成正确、真实且一致的输出,并具有适当的不确定性。
2.安全性 => {暴力、违法、未成年人伤害、成人内容、心理健康问题、隐私侵犯}
a.避免产生不安全和非法的输出,并避免泄露私人信息。
3.公平性 => {不公正、刻板偏见、偏好偏见、性能差异}
a.避免偏见并确保不同人群上性能差异不大。
4.抵制滥用 => {宣传、网络攻击、社交工程、版权泄漏}
a.禁止恶意攻击者滥用。
5.可解释性和推理 => {解释能力不足、逻辑能力不足、 因果能力不足}
a.向用户解释输出并正确推理的能力。
6.社会规范 => {恶毒语言、情感迟钝、文化迟钝}
a.反映普遍共享的人类价值观。
7.稳健性 => {提示攻击、范式和分布变化、干预效果、投毒攻击}
a.对抗性攻击和分布变化的抗性。
本文的分析基于在大模型时代出现的安全和可信任部署挑战,也考虑了已有文献里对可信任人工智能的讨论。同时对主要类别的定义和划分参考了大模型在社会中的应用,尽量确保每个评估的维度在主流的大模型应用中有一定程度的相关性和重要性。具体每个类别及其子类别中的文献和讨论见文章。
对于每个子类别,文章进行相关的调研和讨论,同时也提供了案例分析去阐述相关模型在相关可信任维度上的问题。比如,下面的例子给出了 ChatGPT 在事实类问题上的一些错误:



