
又到换显卡的时候了——如果平台有货、你还有肾的话……
当地时间9月20日,英伟达在 GTC 显卡技术大会上,终于发布了万众期盼的 RTX 40 系列显卡。其中 4090 起步价就高达1599美 元(¥11200+)。
 RTX 4090 渲染图 图片来源:英伟达
RTX 4090 渲染图 图片来源:英伟达
这个价格,难怪发布会后,网友恶搞的图就纷纷上线……
 图片来源:LTT
图片来源:LTT
除了40 系列显卡之外,同场发布的,还有英伟达在图形计算架构、游戏开发、AI加速、工业元宇宙、云计算、量子计算等方面的新产品、技术、最新进展。
它们包括(并不限于):
全新 GPU 架构Ada Lovelace,安培 (Ampere) 架构的升级版,也是40系列显卡性能巨大提升的功臣;
RTX Remix,一个游戏 mod 开发工具,能够为几乎任何3D游戏添加光追效果
“核弹”H100 AI 加速 GPU,已经全面启动生产,即将发货;
“雷神”(Thor) 超级计算机,整合 Grace(CPU)、Ada(GPU)、 Hopper (AI加速计算)三大能力,适用汽车、医疗、工业等领域。以汽车为例,单机即可撑起整个自动驾驶系统+车机+车载娱乐系统;
Omniverse Cloud 服务,能够连接几乎所有主流大型3D工业/设计应用的云端基础设施(IaaS),让元宇宙开发可以在多端任何设备之间无缝工作;
Nemo LLM 系列,一个超大规模神经网络开发工具,能够显著加速大规模神经网络模型的训练、调优和推理等,包括面向自然语言、生物制药等多个场景的子服务。
其中,最新的 Ada Lovelace 架构,可以说是绝大多数新产品和技术突破的背后功臣。这是英伟达推出的全新 GPU架构。主要特性为第三代 RT Core光追核心,吞吐量为前代两倍;第四代 Tensor Core张量核心,张量矩阵计算性能为前代两倍;Ada 架构的 CUDA 核心,显著提高AI加速,以及3D图形计算的性能。

架构来自于“史上第一段电脑程序”的作者,英国数学家艾达·勒芙蕾丝伯爵夫人 图片来源:英伟达
接下来,一起来看这一届英伟达“春晚”,都给大家送上了哪些硬菜。
RTX 4090 & 4080
黄仁勋老板手里拿的这张是英伟达自己的 RTX 4090 Founders Edition(16GB),采用了以往创始人版本基本相同的外壳设计:
 RTX 4090 图片来源:英伟达
RTX 4090 图片来源:英伟达
目前从华硕、七彩虹等合作伙伴那边看到的首批 4090 和 4080 显卡设计普遍采用全尺寸、三风扇、3-slot 厚度:
 ROG Strix RTX 4090 图片来源:华硕 ROG
ROG Strix RTX 4090 图片来源:华硕 ROG
 Vulcan RTX 4090 图片来源:七彩虹
Vulcan RTX 4090 图片来源:七彩虹
RTX 40 系列显卡是:
英伟达最新推出的Ada Lovelace架构的第一款显卡,
采用了最新版 DLSS 3深度学习超级采样技术、
着色器 Shader 执行重新排序 (SER) 技术、
Ada 光流加速器、
第八代英伟达双AV1编码器、
24GB GDDR6X 显存
在游戏性能方面,40 系列最大的性能提升来自于最新版 DLSS 3 技术。
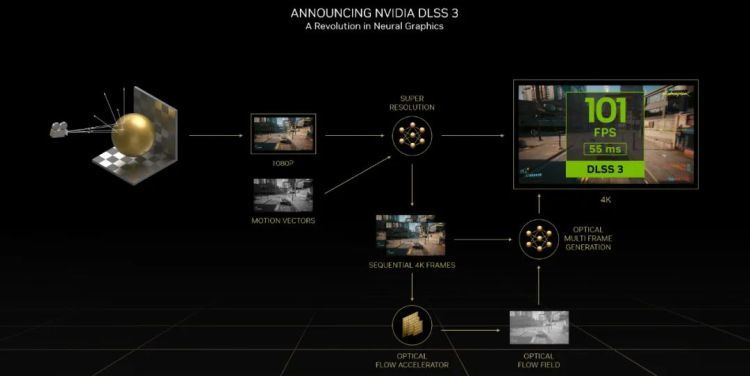
DLSS (Deep Learning Super Sampling,深度学习超级采样)能够调取低分辨率的当前帧和高分辨率的上一帧,使用卷积神经网络 (CNN) 自动编码技术来提前预测出高分辨率的当前帧。
DLSS 3 的最大突破,在于在深度学习超分辨率技术的基础上,增加了光学多帧生成能力,并且集成了英伟达开发的高速低延迟向量计算技术 Reflex。
DLSS 3 采用的 CNN 自动编码器能够接受4个输入:当前帧、上一帧、Ada 光流加速器生成的光流场数据,以及运动矢量+深度等游戏引擎数据。
最厉害的地方在于 Ada 光流加速器:它能够分析两个连续帧,捕捉导粒子、光照、反射、阴影等不包含在游戏运动矢量引擎计算当中的信息,捕捉这些像素在两帧之间移动的方向和速度,从而独立计算出一个光流场。
 Ada 光流场图示 图片来源:英伟达
Ada 光流场图示 图片来源:英伟达
结果就是,从这些数据输入当中,DLSS 3 能够精确计算并重建出当前帧的四分之三,外加下一帧的全部,总体重建了总显示像素的八分之七。这样能够极大地提高了游戏帧率和图形质量,进一步降低传统渲染方式对 GPU 和 CPU 造成的负载。
 DLSS 3 技术图解 图片来源:英伟达
DLSS 3 技术图解 图片来源:英伟达
再加上全新的 Shader 执行重新排序 (SER) 技术,和 CPU 的乱序执行一样,是计算技术领域的重大创新,能够通过动态重新调度 shader 负载,更好地利用 GPU 内的各项资源,将光追性能提高三倍,提升25%左右的帧率
英伟达也找到波兰蠢驴合作开发了一个《赛博朋克2077》的光追过载模式,显示在 RTX 4090 显卡上打开 DLSS 3 之后图像输出延迟降低了一半多,帧率提升了四倍,总体性能提升约为4倍。这个模式回头也会推送给 PC 版玩家,在 40 系列显卡上可以打开。
除了《赛博朋克2077》之外,包括《微软模拟飞行》、新哈利波特游戏、《黑神话:悟空》等在内的30多款游戏,也都将原生支持 DLSS 3 技术:
 图片来源:英伟达
图片来源:英伟达
你的游戏没在列表里?没关系。
为了向游戏爱好者群体里的图形增强 Mod(模组)开发者致敬,英伟达还推出一个模组开发平台,名为 RTX Remix。
 RTX Remix 图示 图片来源:英伟达
RTX Remix 图示 图片来源:英伟达
一边玩游戏,一边打开这个工具,它能够录制游戏场景数据,直接从 GPU 里拦截渲染指令,包括纹理、几何体、照明数据和镜头位置等,将它们转换为通用场景描述(Universal Scene Description, USD)。
然后,再运用多项技术对其自动增强纹理,甚至可以让一些“上古”时代、不支持光追的32位游戏,实现光追和 DLSS 3 支持。
最后,RTX Remix 可以把这些增强结果打包生成为一个游戏 Mod 文件——结果就是,也许大家不用成天上 Nexus Mods 下图形增强模组了,因为有了 RTX Remix,任何人理论上都可以成为模组开发者,自己动手增强自己的游戏体验!
为了更直接地展示 RTX Remix 的能力,英伟达和水管公司合作开发了一个原版《传送门》+RTX 强化版 DLC,画面质量和光影效果有了巨大提升(见下图右)
 Portal RTX DLC 图片来源:英伟达、Valve
Portal RTX DLC 图片来源:英伟达、Valve
总体上,RTX 4090 目前已知只有24GB显存一种配置。在开启了 DLSS 3 时,其在光追游戏中的性能比上一代采用 DLSS 2 的 3090 Ti 显卡快4倍,总体游戏性能提升约为2倍,并且功耗维持在相同的450W。
RTX 4080 有12和16GB显存两种配置,总体游戏性能提升为 3080 Ti 的两倍,在 DLSS 3 开启时性能足以超过 3090 Ti。
游戏说完,再来简单看一下创作者方面:在3D 渲染、视频导出,以及 AI 相关任务方面,RTX 4090 的性能比 3090 Ti 快两倍,4080 16GB 版本则比 3080 Ti 快1.5倍。
RTX 4090 起价1599美元,10月12日面市;4080 两种配置都在今年11月上市,起价分别为899和1199美元。
不少朋友可能在不久前加密矿难的时候,才刚刚入手价格正常的30系列显卡……如果你也是这样,那么接下来的消息可能会让你些许悲伤:30系列显卡的英伟达指导价格也有所下调,比目前市价普遍低了50美元左右……
当然,新品发布也少不了吐槽。
华硕板卡的官方图,Mini-ITX主板+4090,已经不是显卡插在主板上了,而是主板插在显卡上……
 图片来源:华硕
图片来源:华硕
还有网友说,跟去年这个“泄露”版4090 相比,大小似乎没差多少……
 图片来源:Captains Workspace
图片来源:Captains Workspace
另外值得一提的是,就在上周末,全球最大的板卡厂商之一,曾被称为英伟达“亲儿子”的 EVGA,突然正式宣布了和英伟达终止合作关系。尽管该公司已经完成了测试产品开发,量产已经做好准备,却明确表示将不会生产和销售 EVGA 品牌的40系列显卡,30系列存量仅用于售后服务,并且完全退出显卡市场……
至于原因,EVGA 指责英伟达拿自己当小弟、当炮灰,不仅不及时提供产品技术和市场相关信息,还用低价 founders edition 显卡打击合作伙伴的销售,一度逼得 EVGA、华硕等板卡厂商下调价格。
毫无疑问的是,英伟达一边继续在显卡技术上做出大跨步式的创新,另一边由于自己的技术和市场领袖地位,确实在板卡合作方那边显得傲慢至极——不只是 EVGA 一家,其它厂商都有相同感受,只是没有像它这么坚决而已。
“雷神”车载超级计算机
大家应该知道,随着近十年来 GPU 技术驱动的深度学习突飞猛进,英伟达早已不再是纯粹的传统消费显卡厂商,也已成为了工业级 AI 加速计算方面的技术领导者。
在今天的 GTC 大会上,英伟发布了 DRIVE Thor,一台只靠单机架构,就能够运行自动驾驶+数字仪表盘/车机+车载信息娱乐一整套系统的车规超级计算机:
 DRIVE Thor 图片来源:英伟达
DRIVE Thor 图片来源:英伟达
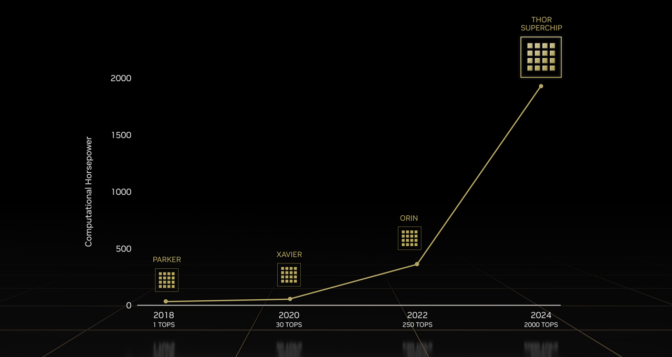
“雷神”超级计算机,可以说是英伟达三大 AI 加速计算架构技术之集大成:Grace CPU、Ada Lovelace 架构 GPU,以及 Hopper 多实例 GPU 架构。它的总体浮点运算性能高达2000万亿次 (TFlops),比前不久刚刚实现商用的前代平台 DRIVE Orin ,算力实现了惊人的八倍提升。
这次升级的另一大亮点,在于英伟达首次在面向自动驾驶场景开发的车载计算机 DRIVE 平台中,增加了 Transformer(一种主流的深度学习模型)模型的支持。
Transformer 引擎在“雷神” GPU 单元的H100Tensor Core中运行,依靠 FP8(8位浮点)精度,它能够直接在车载计算机上运行包括 Transformer 在内的更大规模的机器学习模型,从视频当中截取感知帧,极大提升了车载算力的性能,降低了对云端服务器和连通性的要求。
黄仁勋在 GTC 演讲中演示了一段视频,显示“雷神”可以只靠自己就运行一辆自动驾驶汽车完整的运行、感知、决策、避让等操作,以及环境实时扫描和数据搜集等任务。
 DRIVE Thor roadmap 图片来源:英伟达
DRIVE Thor roadmap 图片来源:英伟达
“雷神”的另一个特性在于具备多域计算 (multi-domain computing) 能力,满足车规级硬件的要求。
在汽车行业,车机、自动/辅助驾驶系统对于稳定性安全性较高,而车载信息娱乐系统没有那么高。过去,这些不同类型和安全级别的功能需要数十个 ECU(可以理解为独立的小电脑)来控制。
而“雷神”可以在系统层面对不同任务进行多域隔离,使得诸如自动/辅助驾驶、车机仪表、安全气囊等关键进程能够不间断的进行。
一台“雷神”上可以同时运行 QNX(主要用于车规级系统和功能)、Linux 和 Android(更多用于信息娱乐等非关键系统)。
 图片来源:英伟达
图片来源:英伟达
目前,包括小鹏 (Xpeng)、吉利极氪 (Zeekr)、轻舟 (Qcraft) 等在内的一些国内新能源/新造车品牌和自动驾驶技术开发者,已经和英伟达达成合作关系,对“雷神”进行早期测试。
英伟达估计“雷神”系统将在2024年进入量产,极氪 CEO 安聪慧透露将在2025年生产的下一代智能电动汽车当中采用该系统。
正如历年来英伟达的产品发布会和技术峰会一般,本届 GTC 也是发布种类繁多、信息量巨大且密集。
除了我们刚刚介绍的 RTX 40系列显卡和“雷神”车载超算之外,英伟达还推出了依赖最新 Ada Lovelace 架构 GPU 的云计算服务、边缘计算平台、工业园元宇宙开发环境 Omniverse Cloud、面向大语言/蛋白质折叠模型优化的加速计算工具和服务等,碍于篇幅限制,在此就不详述,感兴趣的朋友可以访问英伟达官网 newsroom 查看。



